模型结构¶
Monolith 在 TensorFlow 基础上扩展了动态 Embedding Hash Table,除此之外,模型结构的定义几乎与原生 TensorFlow 无异。 同时,Monolith 预置提供了封装好的 dense layer 供用户使用。
1. 精排模型¶
demo 展示了一个典型精排模型的编写。
2. 召回模型¶
模型结构¶
目前召回一般是 FFM 结构
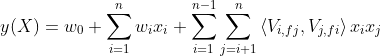
每个特征被划分成 K 个 field,特征在每个 field 都会有单独的 embedding,计算二次项参数时, 根据两个特征所属的 field 使用不同的 embedding 计算点乘。目前通用的召回模型是简化版的三域 FFM, 即将 user,group(item),context 作为三个 field,每个特征都有两部分 embedding, 分别对应其他两个 field。 如下图所示,128 维的 embedding 分成低 64 维和高 64 维,两两点乘实现交叉,为了减少计算,field内部先进行了 sum_pooling 处理。
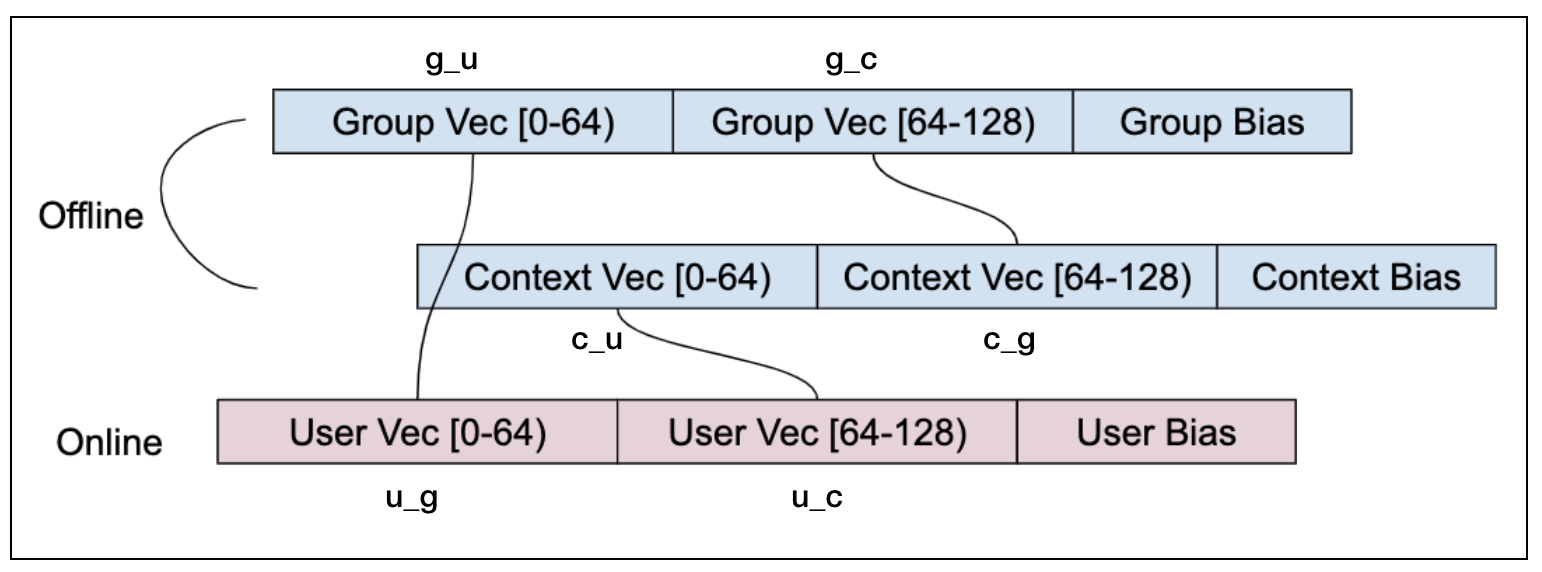
因此 FFM 的计算公式转化成:
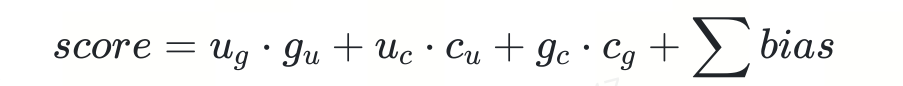
其中
group 和 context 是已知的
g_c * c_g 部分和 group bias 可以离线计算得到
u_c 、c_u 、context bias、user_bias在一次请求中是固定的,与 group 排序无关,可以省略
u_g * g_u 部分需要在线计算
因此 FFM 线上 serving 时,需要实现两部分工作:
离线计算 offline_score = g_c * c_g + group bias,这部分通过 fermat 模块实现
在线计算 u_g * g_u + offline score , 这部分是 viking 实现
模型编写¶
召回模型与精排模型编写几乎无异,但值得注意的是,由于召回模型在 serving 阶段天然与精排模型有差异,所以召回模型导出 serving 图时需要一些额外操作。 一般类似如下代码定义了召回 FFM 所需要的所有 part
def model_fn(self, features: Dict[str, tf.Tensor],
mode: tf.estimator.ModeKeys):
item_embeddings = self.lookup_embedding_slice(features=ITEM_FNAMES,
slice_name='item_emb',
slice_dim=32, **deep)
user_embeddings = self.lookup_embedding_slice(features=USER_FNAMES,
slice_name='user_emb',
slice_dim=32, **deep)d
context_embeddings = self.lookup_embedding_slice(features=CONTEXT_FNAMES,
slice_name='context_emb',
slice_dim=32, **deep)
user_lr_concat = self.lookup_embedding_slice(features=USER_FNAMES,
slice_name='lr_weight',
slice_dim=1, **wide)
item_lr_concat = self.lookup_embedding_slice(features=ITEM_FNAMES,
slice_name='lr_weight',
slice_dim=1, **wide)
context_lr_concat = self.lookup_embedding_slice(features=CONTEXT_FNAMES,
slice_name='lr_weight',
slice_dim=1, **wide)
user_bias = tf.reduce_sum(tf.add_n(user_lr_concat), axis=1, name='user_lr')
item_bias = tf.reduce_sum(tf.add_n(item_lr_concat), axis=1, name='item_lr')
context_bias = tf.reduce_sum(tf.add_n(context_lr_concat), axis=1, name='context')
item_sum_pooling = tf.add_n(item_embeddings)
user_sum_pooling = tf.add_n(user_embeddings)
context_sum_pooling = tf.add_n(context_embeddings)
user_embedding = tf.identity(user_sum_pooling, name='user_embedding')
item_embedding = tf.identity(item_sum_pooling, name='item_embedding')
context_embedding = tf.identity(context_sum_pooling, name='cid_tensor')
在 model_fn 中要特别加上以下代码,以便 serving 图正确导出
if mode == tf.estimator.ModeKeys.PREDICT:
self.add_extra_output(
"user_subgraph", {
"user_embedding": user_embedding,
"cid_tensor": context_embedding,
"user_lr": user_bias,
"context": context_bias
})
self.add_extra_output("item_subgraph", {
"item_embedding": item_embedding,
"item_lr": item_bias
})
3. Multi-task 模型¶
Monolith 同样支持 multi-task(multi-head) 模型训练,只需要保证 model_fn 返回的 EstimatorSpec 符合 multi-task 编写规则即可
def input_fn(self, mode) -> 'DatasetV2':
def parser(tensor):
extra_features = ['sample_rate', 'actions']
extra_feature_shapes = [1] * len(extra_features)
features = parse_examples(tensor,
sparse_features=VALID_NAMES,
extra_features=extra_features,
extra_feature_shapes=extra_feature_shapes)
if mode != tf.estimator.ModeKeys.PREDICT:
actions = tf.reshape(features['actions'], shape=(-1,))
features['label_ctr'] = tf.where(tf.math.equal(actions, 1),
tf.ones_like(actions, dtype=tf.float32),
tf.zeros_like(actions, dtype=tf.float32))
features['label_cvr'] = tf.where(tf.math.equal(actions, 2),
tf.ones_like(actions, dtype=tf.float32),
tf.zeros_like(actions, dtype=tf.float32))
features['sample_rate'] = tf.reshape(features['sample_rate'], shape=(-1,))
return features
dataset = PBDataset()
dataset = dataset.batch(self.batch_size, drop_remainder=True)
dataset = dataset.map(parser)
return dataset
def model_fn(self, features: Dict[str, tf.Tensor], mode: tf.estimator.ModeKeys):
...
label_ctr = features.get('label_ctr', None)
label_cvr = features.get('label_cvr', None)
return EstimatorSpec(label=[label_ctr, label_cvr],
pred=[pred_ctr, pred_cvr],
head_name=['ctr', 'cvr'],
loss=loss,
optimizer=optimizer,
classification=[True, True])
其中,labels, preds, head_names, classifications 是等长的数组,分别存储对应 task(head) 的 label(Tensor),
pred(Tensor), head_name(str), classification(bool)。